2nd and 3rd of March 2026, Passau University (Germany)






























To register, send your full name, affiliation, and, where applicable, title and abstract of your talk to heil@fim.uni-passau.de. Please register before January 30, 2026.
Update: Registrations are closed.
Venue: Room SR029, Wirtschaftwissenschaften.
Address: Innstraße 27, 94032 Passau, Germany.
The university's contact pages include maps and directions.
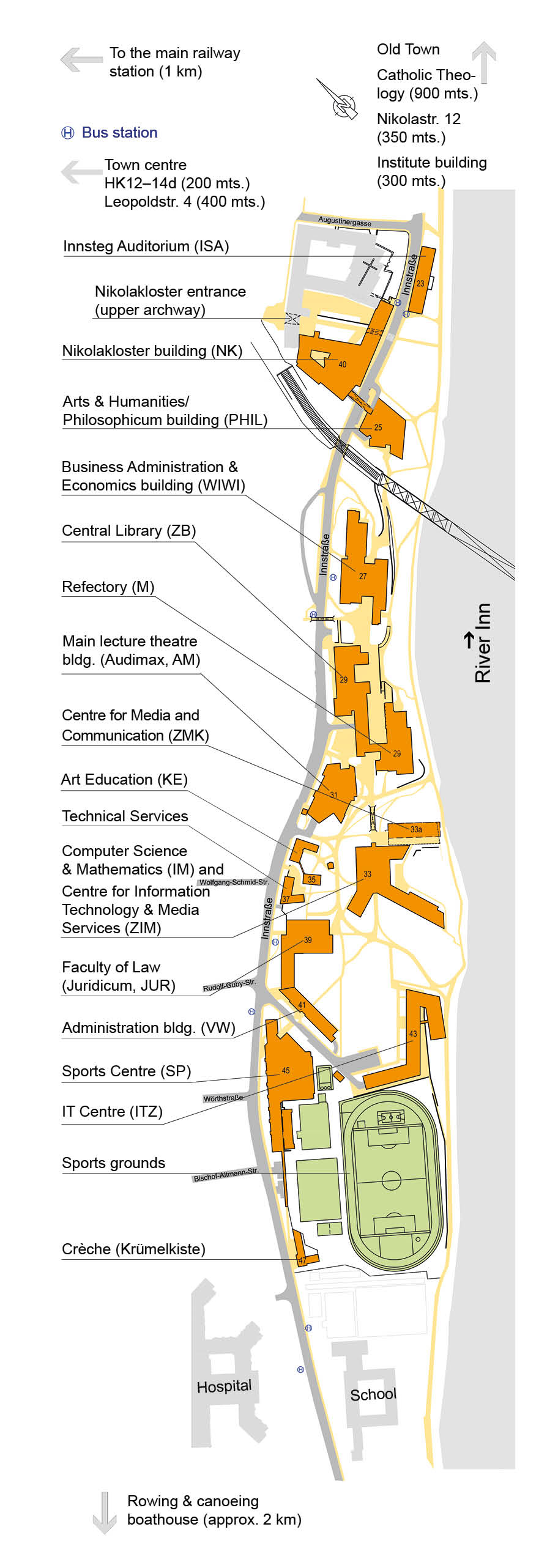
Most parts of the University of Passau are within walking distance – and the same is true of Passau itself. For a quick overview, see the city map with university buildings and the campus map.
| Time | Event | |
|---|---|---|
| 12:00 | Arrival & Snacks | |
| 13:15 | Welcome | |
| 13:25 | Moritz Müller | Simple general magnification |
| 13:50 | Yijia Chen | Understanding Uncolored CFI-graphs |
| 14:15 | Tomáš Novotný | Robust graph isomorphism and other quadratic assignment problems parametrised by VC dimension |
| 14:40 | Pause | |
| 15:10 | Martin Lange | A Bisimulation-Invariance-Based Approach to the Separation of Polynomial Complexity Classes |
| 15:35 | Steffen van Bergerem | Algorithmic Metatheorems for Clique-Guarded First-Order Logic with Counting |
| 16:00 | Johannes Lange | Multiclass Classification using Clique-Guarded First-Order Logic with Counting |
| 16:25 | Pause | |
| 16:45 | Tim Seppelt | Lower Bounds in Algebraic Complexity via Symmetry and Homomorphism |
| 17:10 | Matthäus Micun | Proof Complexity using structured Circuits |
| 19:30 | AlMoTh Dinner | Heilig Geist Stiftskeller, Heiliggeistgasse 4 |
| Time | Speaker | Event |
|---|---|---|
| 09:00 | Ahmet Kara | From Shapley Value to Model Counting and Back |
| 09:25 | Kord Eickmeyer | Reconfiguration Problems and Token Jumping Logic |
| 09:50 | Janik Hammerer | A Compendium of Regular Expression Shapes in SPARQL Queries |
| 10:15 | Pause | |
| 10:30 | Daniel Albert | Maintaining Longest Common Extensions in Dyn-FO |
| 10:55 | Jenny Stimpson | Constant time testability of first-order logic with modulo counting on finitary graphs |
| 11:20 | Nils Vortmeier | Dynamic Planar Graph Isomorphism is in DynFO |
| 11:45 | Pause | |
| 12:05 | Benedikt Pago | Arity hierarchies for quantifiers closed under partial polymorphisms |
| 12:30 | Hubie Chen | Optimally Rewriting Formulas and Database Queries: A Confluence of Term Rewriting, Structural Decomposition, and Complexity |
Address: Heiliggeistgasse 1, 94032 Passau
Phone: +49(0)851 98693898
Address: Kapuzinerstraße 32, 94032 Passau
Phone: +49(0)851 7566660
Address: Bahnhofstr. 24, 94032 Passau
Phone: +49(0)851 756866 0
Address: Danziger Straße 20, 94036 Passau
Phone: +49(0)851 98844 0
Address: Danziger Straße 42-44, 94036 Passau
Phone: +49(0)851 72040
Address: Untere Donaulände 1, 94032 Passau
Phone: +49(0)851 3850
Address: Rindermarkt 2, 94032 Passau
Phone: +49(0)851 931060
Address: Adalbert-Stifter-Str. 12, 94032 Passau
Phone: +49(0)851 6446
Address: Regensburger Str. 21, 94036 Passau
Phone: +49 (0)851 9879390
Address: Ritz-Schäffer-Promenade 6, 94032 Passau
Phone: +49(0)851 989020
We construct so-called distinguishers, sparse matrices that retain some properties of error correcting codes. They provide a technically and conceptually simple approach to magnification. We generalize and strengthen known general (not problem specific) magnification results and in particular achieve magnification thresholds below known lower bounds. For example, we show that fixed polynomial formula size lower bounds for NP are implied by slightly superlinear formula size lower bounds for approximating any sufficiently sparse problem in NP. We also show that the thresholds achieved are sharp. Additionally, our approach yields a uniform magnification result for the minimum circuit size problem. This seems to sidestep the localization barrier.
The CFI-graphs, named after Cai, Fuerer, and Immerman, are central to
the study of the graph isomorphism testing and of fixed-point logic
with counting. They are colored graphs, and the coloring plays a role
in many of their applications. As usual, it is not hard to remove the
coloring by some extra graph gadgets, but at the cost of blowing up
the size of the graphs and changing some parameters of them as well.
Since their introduction, it has been shown that certain uncolored
variants of CFI-graphs serve the same purposes as the original colored
graphs. We prove that this in fact remains true for the graphs
obtained by simply forgetting the colors from the original CFI-graphs.
To establish this, we provide a systematic analysis of the
automorphism groups of the uncolored CFI-graphs. Furthermore, using
the linear-algebraic framework introduced by Roberson, we investigate
homomorphism counts on these graphs.
Joint work with Joerg Flum (Freiburg) and Mingjun Liu (Regensburg)
Arora et al. [Math. Program. 92, 2002] introduced a randomised quasipolynomial-time algorithm for approximating the solution of quadratic assignment problems (QAP). We define a notion of VC dimension for QAPs and show that it generalises existing notions in special cases, such as graph edit distance approximation. We prove that QAPs of bounded VC dimension admit (randomised) polynomial-time approximation algorithms. Finally, for the problem of approximating graph isomorphism, we analyse the Weisfeiler-Leman dimension for general graphs, as well as for graphs of bounded VC dimension and bounded color-class size. This is a joint work with Anatole Dahan, Martin Grohe, and Daniel Neuen.
We take two results about the polyadic mu-calculus - Otto's Theorem stating that it captures P modulo bisimilarity, as well as a product construction on graphs used for model checking -, some bisimulation-invariant problems that are hard for NP, resp. PSPACE, and work out a characterisation of the separation of P from NP, resp. PSPACE, by means of combinatorial properties of certain tree languages. This is joint work with Florian Bruse.
In this talk, I introduce clique-guarded first-order logic with counting (cgFOC), a fragment of the first-order logic with counting FOC [Kuske and Schweikardt, LICS 2017], and I present algorithmic metatheorems for this fragment. Prior work by Grohe and Schweikardt shows that the model-checking problem for the fragment FOC1 of FOC can be solved in almost-linear time on classes of locally bounded expansion. On the other hand, for the full logic FOC, they showed that the model-checking problem is already AW[*]-hard for the class of (unranked) trees. For cgFOC, which is significantly more expressive than FOC1, I present algorithms for constant-time query answering and constant-delay enumeration after almost-linear-time preprocessing on classes of locally bounded expansion. In addition, I present an almost-linear-time algorithm for probably approximately correct (PAC) learning for Boolean concepts definable in cgFOC on classes of locally bounded expansion. On the other hand, I will show that a slight extension of cgFOC is already intractable on trees.
This is joint work with Johannes Friedrich Lange and Nicole Schweikardt
In this talk, I present model-theoretic and learning-theoretic results on the newly introduced clique-guarded first-order logic with counting (cgFOC), which is a fragment of the first-order logic with counting FOC [Kuske and Schweikardt, LICS 2017]. There is already a well-studied logical framework for probably approximately correct (PAC) learning with binary classification. Learnability in the binary case is strongly connected to the Vapnik-Chervonenkis (VC) dimension, for which I show a computable bound for cgFOC formulas on nowhere dense relational structures. In order to handle a multiclass classification setting with an infinite number of classes, I also show results on the graph dimension, a generalisation of the VC dimension to the multiclass setting. Based on these results, I present algorithms for learning cgFOC-definable multiclass concepts on classes of locally bounded expansion and for FOC-definable multiclass concepts on classes of bounded degree.
This is joint work with Steffen van Bergerem and Nicole Schweikardt.
Valiant’s conjecture from 1979 asserts that the circuit complexity classes VP and VNP are distinct, meaning that the permanent does not admit polynomial-size algebraic circuits. As it is the case in many branches of complexity theory, the unconditional separation of these complexity classes seems elusive. In stark contrast, the symmetric analogue of Valiant’s conjecture has been proven by Dawar and Wilsenach (2020): the permanent does not admit symmetric algebraic circuits of polynomial size, while the determinant does. Symmetric algebraic circuits are both a powerful computational model and amenable to proving unconditional lower bounds. In this paper, we develop a symmetric algebraic complexity theory by introducing symmetric analogues of the complexity classes VP, VBP, and VF called symVP, symVBP, and symVF. They comprise polynomials that admit symmetric algebraic circuits, skew circuits, and formulas, respectively, of polynomial orbit size. Having defined these classes, we show unconditionally that symVF ⊊ symVBP ⊊ symVP.
To that end, we characterise the polynomials in symVF and symVBP as those that can be written as linear combinations of homomorphism polynomials for patterns of bounded treedepth and pathwidth, respectively. This extends a previous characterisation by Dawar, Pago, and Seppelt (2025) of symVP. The separation follows via model-theoretic techniques and the theory of homomorphism indistinguishability.
Although symVBP and symVP admit strong lower bounds, we are able to show that these complexity classes are rather powerful: They contain homomorphism polynomials which are VBP- and VP-complete, respectively. Vastly generalising previous results, we give general graph-theoretic criteria for homomorphism polynomials and their linear combinations to be VBP-, VP-, or VNP-complete. These conditional lower bounds drastically enlarge the realm of natural polynomials known to be complete for VNP, VP, or VBP. Under the assumption VFPT /= VW[1], we precisely identify the homomorphism polynomials that lie in VP as those whose patterns have bounded treewidth and thereby resolve an open problem posed by Saurabh (2016).
Joint work with Benedikt Pago and Prateek Dwivedi.
Sentential Decision Diagrams (SDDs) are data structures, which can succinctly represent many Boolean functions, while still having certain nice algorithmic properties, such as polynomial-time satisfiability checking. Moreover, SDDs are exponentially more succinct than Ordered Binary Decision Diagrams (OBDDs).
Atserias, Kolaitis, and Vardi (2004) introduced a proof system, which verifies whether a given CNF is unsatisfiable by encoding proof lines as OBDDs. This method was later extended to a larger family of OBDD-based proof systems. In this talk, we introduce proof systems that instead rely on SDDs, and compare them to well-known versions of OBDD-based proof systems.
This is joint work with Christoph Berkholz.
In this paper we investigate the problem of quantifying the contribution of each variable to the satisfying assignments of a Boolean function based on the Shapley value.
Our main result is a polynomial-time equivalence between computing Shapley values and model counting for any class of Boolean functions that are closed under substitutions of variables with disjunctions of fresh variables. This result settles an open problem raised in prior work, which sought to connect the Shapley value computation to probabilistic query evaluation.
We show two applications of our result. First, the Shapley values can be computed in polynomial time over deterministic and decomposable circuits, since they are closed under OR-substitutions. Second, there is a polynomial-time equivalence between computing the Shapley value for the tuples contributing to the answer of a Boolean conjunctive query and counting the models in the lineage of the query. This equivalence allows us to immediately recover the dichotomy for Shapley value computation in case of self-join-free Boolean conjunctive queries; in particular, the hardness for non-hierarchical queries can now be shown using a simple reduction from the #P-hard problem of model counting for lineage in positive bipartite disjunctive normal form.
This talk presents joint work with Dan Olteanu and Dan Suciu.
Regular path queries (RPQs) are at the heart of navigational queries in graph databases. Motivated by new features of regular path queries in the languages Cypher, GQL, and SQL/PGQ, which require new approaches for indexing and compactly storing intermediate query results, we investigate a large corpus of real-world RPQs. Our corpus consists of 148.7 million RPQs occurring in 937.2 million SPARQL queries, used on 29 different data sets. We investigate three main questions on these logs. First, what is the syntactic structure of these RPQs? Second, how much non- determinism (or ambiguity) do they have? Third, do they admit tractable evaluation under simple path and trail semantics? Concerning the first question, we show that all the RPQs can be classified in only 572 different syntactic shapes, which we provide in a downloadable data set in Zenodo. Furthermore, we classify the relative use of various RPQ operators, and popular predicates that are used for transitive navigation. Concerning the second question, we show that although non-determinism occurs in the RPQs, less than one in ten million requires a deterministic finite automaton with more states than the size of the regular expression. This is remarkable because this blow-up is known to be exponential in the worst case. Concerning the last question, the vast majority of expressions admits tractable evaluation.
A longest common extension (LCE) query on a string computes the length of the longest common suffix or prefix at two given positions. A dynamic LCE algorithm maintains a data structure that allows efficient LCE queries on a string that can change via character insertions and deletions.
A dynamic problem is in Dynamic First-Order Logic (Dyn-FO) if it can be maintained and queried in first order logic, i.e. there is a dynamic algorithm where the actions invoked by queries and updates are expressible as first-order formulae. The queries and updates of a Dyn-FO algorithm can also be expressed as parallel constant-time algorithms, which is useful to analyze the work of a Dyn-FO algorithm.
A Dyn-FO algorithm is presented that can maintain LCE queries with O(n^ϵ) work, for any ϵ > 0. The algorithm maintains string synchronizing sets to answer LCE queries. A string synchronizing set tracks all occurrences of a carefully chosen selection of substrings within the original string. To maintain these synchronizing sets in DynFO, the algorithm allows parts of its information to become outdated by some number of updates. It answers queries by combining this slightly outdated information with a list of the recent changes.
Two applications of this Dyn-FO LCE algorithm are shown. Firstly, a Dyn-FO algorithm can maintain membership in a Dyck language Dk, k > 0 with O(n^ϵ) work for any ϵ > 0. Secondly, a Dyn-FO algorithm can maintain squares within a string with O(n^ϵ) work for any ϵ > 0.
I will present recent results and methods regarding property testing with constant running time in the bounded degree model. In particular I will show that properties expressible in first order logic with modulo counting (FOMOD) are testable in constant time on graph classes with bounded component size c and bounded degree d. To this end I will give a tailored version of Hanf normal form and demonstrate how a result from number theory can be used to infer global information about the input graph based on a constant size sample.
Consider two planar graphs which are subject to edge insertions and deletions. We show that whether the two graphs are isomorphic can be maintained with first-order logic formulas and auxiliary data of polynomial size. This places the dynamic planar graph isomorphism problem into the dynamic descriptive complexity class DynFO. As a consequence, there is a dynamic constant-time parallel algorithm with polynomial-size auxiliary data which maintains whether two dynamic planar graphs are isomorphic.
This talk presents joint work with Samir Datta, Asif Khan, Felix Tschirbs and Thomas Zeume.
We investigate the expressive power of generalized quantifiers closed under partial polymorphism conditions motivated by the study of constraint satisfaction problems. We answer a number of questions arising from the work of Dawar and Hella (CSL 2024) where such quantifiers were introduced. For quantifiers closed under partial near-unanimity polymorphisms, we establish hierarchy results clarifying the interplay between the arity of the polymorphisms and of the quantifiers: The expressive power of (ℓ + 1)-ary quantifiers closed under ℓ-ary partial near-unanimity polymorphisms is strictly between the class of all quantifiers of arity ℓ - 1 and ℓ. We also establish an infinite hierarchy based on the arity of quantifiers with a fixed arity of partial near-unanimity polymorphisms. Finally, we prove inexpressiveness results for quantifiers with a partial Maltsev polymorphism. The separation results are proved using novel algebraic constructions in the style of Cai-Fürer-Immerman and the quantifier pebble games of Dawar and Hella (2024).
Joint work with Anuj Dawar and Lauri Hella.
A central computational task in database theory, finite model theory, and computer science at large is the evaluation of a first-order sentence on a finite structure. In the context of this task, the width of a sentence, defined as the maximum number of free variables over all subformulas, has been established as a crucial measure, where minimizing width of a sentence (while retaining logical equivalence) is considered highly desirable.
An undecidability result rules out the possibility of an algorithm that, given a first-order sentence, returns a logically equivalent sentence of minimum width; this result motivates the study of width minimization via syntactic rewriting rules, which is this article's focus. For a number of common rewriting rules (which are known to preserve logical equivalence), including rules that allow for the movement of quantifiers, we present an algorithm that, given a positive first-order sentence \phi, outputs the minimum-width sentence obtainable from \phi via application of these rules. We thus obtain a complete algorithmic understanding of width minimization up to the studied rules; this result is the first oneof which we are awarethat establishes this type of understanding in such a general setting. Our result builds on the theory of term rewriting and establishes an interface among this theory, query evaluation, and structural decomposition theory.
This is joint work with Stefan Mengel which appeared in ICDT '24.










{kind=link}